이번에는 Find 함수를 이용해 보겠습니다.

1. Find 함수의 구문
FIND(find_text, within_text, [start_num])입니다.
다른 함수의 경우와는 다르게
찾을 문자열이 먼저 나오고, 찾을 대상 주소가 두 번째로 나옵니다.
2. 첫 번째 원문자의 위치 찾기
가. 마지막 글자가 원문자 1인 경우 찾기
역시 B3을 대상으로 먼저 해보겠습니다.
원문자 1은 Unicode가 9312입니다.
그리고, 문자열을 하나씩 분리해야 하므로 Mid 함수를 사용합니다.
그런데, 길이를 알아도 1부터 길이까지 연속으로 글자가 생성돼야 하는데,
Sequence 함수를 사용할 수 없다면
아래와 같이 배열을 이용해서 {1,2,3,4,5,6,7,8,9,10}라고 최대 10글자라고 생각하고 배열을 만들었습니다.
그러면, 수식은
=find(9312,unicode(mid(b3,,{1,2,3,4,5,6,7,8,9,10},1)))
이 되고(낮은 버전이라면 수식 입력 후 Ctrl + Shift + Enter키를 눌러야 할 겁니다),

결괏값이 배열의 개수인 10개 나오는데, Unicode값이 9312가 아니면 #VALUE! 오류 메시지가 보이고, 8번째가 원문자 1이고, Mid 수식의 결과로 보면 첫 번째 위치이기 때문에 1로 표시됩니다.
1을 8로 표시해 보겠습니다.
오류면 값이 표시되지 않도록 IsNumber 함수를 이용해 숫자인 경우만 1에서 10의 값을 표시하도록 하겠습니다.
그러면 수식은
=IF(ISNUMBER(FIND(9312,UNICODE(MID(B3,{1,2,3,4,5,6,7,8,9,10},1)))),{1,2,3,4,5,6,7,8,9,10})로서
숫자인 경우만 해당 숫자를 표시하고, 아니면 value_if_false 값이 없으로 False로 표시됩니다.

이제 8이라는 값을 알았으니
Min함수를 이용해 최솟값을 구하면 됩니다.
=MIN(IF(ISNUMBER(FIND(9312,UNICODE(MID(B3,{1,2,3,4,5,6,7,8,9,10},1)))),{1,2,3,4,5,6,7,8,9,10}))
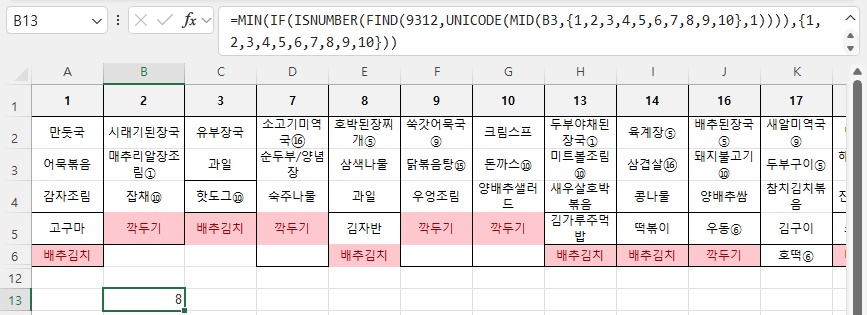
원하는 값 8이 나왔습니다. 8번째 문자가 원문자 1이라는 것입니다.
나. 원문자 1부터 20인 문자의 위치 찾기
이번에는 Unicode가 아니라 Unichar를 사용해서 B3에서 해당하는 원문자의 위치를 찾도록 합니다.
=FIND(UNICHAR({9312,9313,9314,9315,9316,9317,9318,9319,9320,9321,9322,9323,9324,9325,9326,9327,9328,9329,9330,9331}),B3)
라고 입력하니 처음 값이 8로 나오고, 나머지는 해당하는 원문자가 없으므로 #VALUE!로 표시되는데, 총 20개가 표시됩니다.

그런데 첫 번째 위치만 알면 그 위치-1만 가져오면 되므로
index 함수를 이용하면 됩니다.
index 함수의 구문은
INDEX(array, row_num, [column_num])이므로
=INDEX(FIND(UNICHAR({9312,9313,9314,9315,9316,9317,9318,9319,9320,9321,9322,9323,9324,9325,9326,9327,9328,9329,9330,9331}),B3),1)라고 해도 되고,
=INDEX(FIND(UNICHAR({9312,9313,9314,9315,9316,9317,9318,9319,9320,9321,9322,9323,9324,9325,9326,9327,9328,9329,9330,9331}),B3),,1)라고 해도 됩니다.
첫 번째 수식을 입력하니 8이 구해졌습니다.
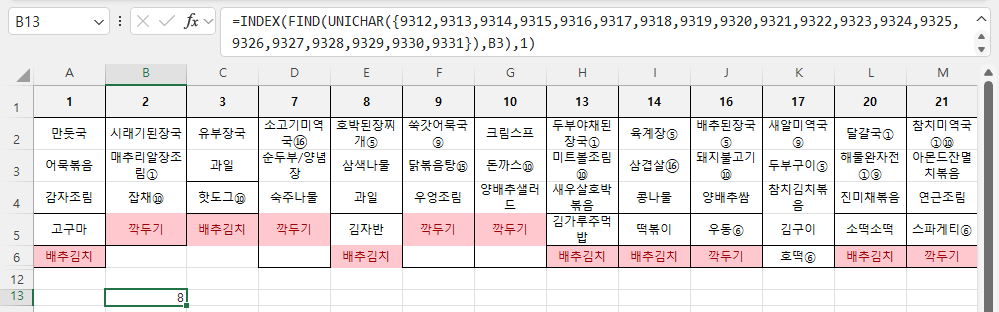
그런데 B13셀의 채우기 핸들을 아래로 끌면 3이 아니라 #VALUE! 에러가 발생합니다.
수식에서 Find부터 ,b4)까지 마우스로 끌어서 범위를 잡은 다음

F9키를 누르니, 해당하는 원문자, 여기서는 ⑩,의 위치에 숫자 3이 표시됩니다.

따라서, 최솟값을 구해야 하는데, 오류가 있으므로 ifError함수를 이용해 오류일 때 값을 10보다 1이 큰 11로 지정합니다.
Esc키를 눌러 원래 수식으로 돌립니다.
그러면 수식에서 index를 min으로 수정합니다.
=MIN(IFERROR(FIND(UNICHAR({9312,9313,9314,9315,9316,9317,9318,9319,9320,9321,9322,9323,9324,9325,9326,9327,9328,9329,9330,9331}),B4),11))
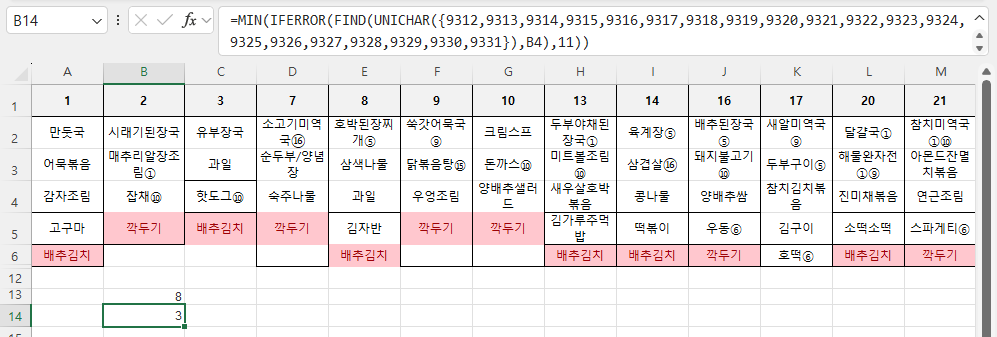
이제 B14셀의 채우기 핸들을 B13셀로 끌어 수식을 복사합니다.
3. 원문자를 제외한 문자열 가져오기 1
이제 Left함수를 이용해서 첫 번째 원문자 위치 전까지만 문자열을 가져오면 됩니다.
B13셀의 수식 앞에 Left(b3,를 입력하고, 마지막에 -1)로 닫으면 됩니다.
=LEFT(B3,MIN(IFERROR(FIND(UNICHAR({9312,9313,9314,9315,9316,9317,9318,9319,9320,9321,9322,9323,9324,9325,9326,9327,9328,9329,9330,9331}),B3),11))-1)
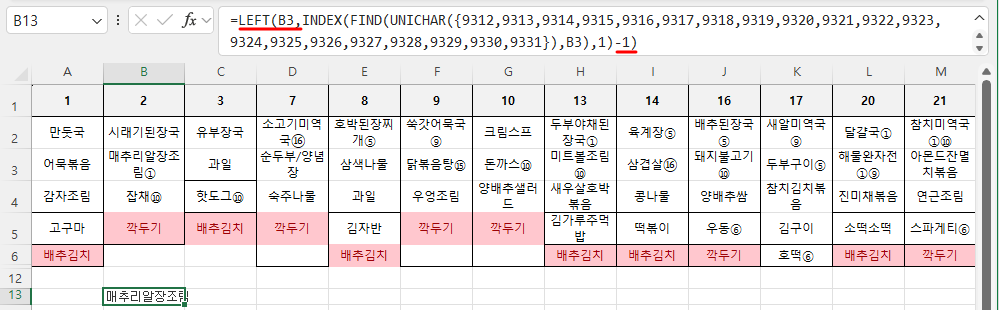
이제 B13셀의 수식은 A12셀부터 U16셀까지 붙여 넣으면 됩니다.
글자의 크기를 11에서 9로 바꾼 후 살펴보면 원문자 1개이거나 2,3개 모두 잘 됩니다.
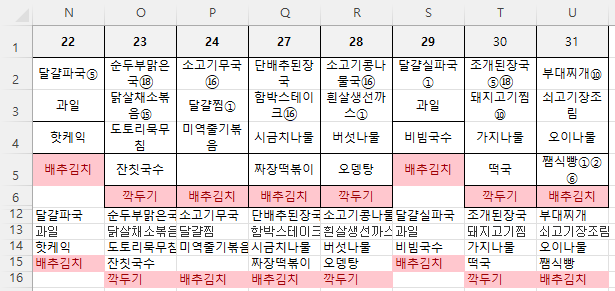
4. 원문자를 제외한 문자열 가져오기 2
연속된 숫자를 일일이 입력했는데,
Sequence 함수를 이용하면 간단하게 할 수 있습니다.
그러나 Sequence함수는 Microsoft 365용 Excel Mac용 Microsoft 365용 Excel 웹용 Excel Excel 2021 Mac용 Excel 2021 iPad용 Excel iPhone용 Excel Android 태블릿용 Excel Android 휴대폰용 Excel에서만 사용가능합니다.
Sequence 함수의 구문은
=SEQUENCE(rows,[columns],[start],[step])로서
첫 번째 인수인 행 수만 필수이고, 나머지는 모두 옵션입니다.
{9312,9313,9314,9315,9316,9317,9318,9319,9320,9321,9322,9323,9324,9325,9326,9327,9328,9329,9330,9331}을
Sequence(20,,9312) 또는 Sequence(,20,9312) 로 바꿀 수 있습니다.
rows가 필수이지만 입력하지 않으면 1로 설정됩니다.
B13셀의 값이 잘 보이지 않으므로 B16셀 수식까지만 바꾸면 아래와 같습니다.
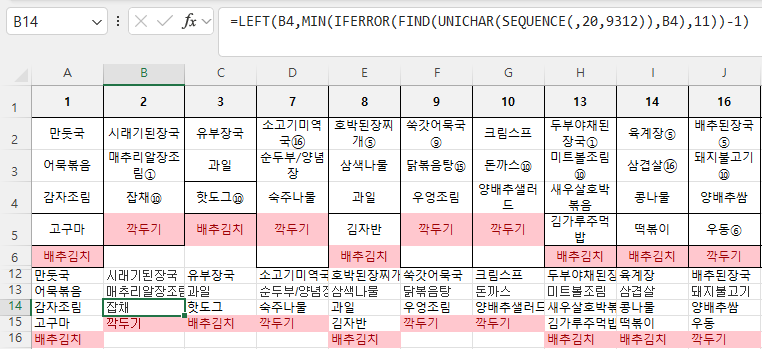
원문자가 있거나 하나만 있거나 잘 됩니다.
그러나 배열을 이용해서 첫 번째 원문자의 위치를 찾아서 첫 번째 원문자 전까지만 문자열을 가져오는 것은 원문자 다음에 원문자가 아닌 것이 나오면 문제가 있는 단점이 있습니다.
따라서, 다음에는 원문자의 위치에 관계없이 원문자를 제거하는 것을 해보겠습니다.
'Excel' 카테고리의 다른 글
| 문자열 중 원문자 지우기(4) - Scan, Reduce (0) | 2024.05.14 |
|---|---|
| 문자열 중 원문자 지우기(3) - TextJoin, Sequence (0) | 2024.05.13 |
| 문자열 중 원문자 지우기(1) - Unicode, Substitute (0) | 2024.05.09 |
| 하나라도 일치하는 건 수 세기 (0) | 2024.05.08 |
| 선입선출법에 따른 재고 구하기 (0) | 2024.05.07 |



