1편에서 작업한 내용을 이어서 설명하겠습니다.
https://lsw3210.tistory.com/manage/newpost/337?type=post&returnURL=https%3A%2F%2Flsw3210.tistory.com%2Fentry%2F%ED%8C%8C%EC%9B%8C-%EC%BF%BC%EB%A6%AC%EB%B3%80%ED%99%98%EC%9D%98-%EC%B6%94%EC%B6%9C%EA%B3%BC-%EC%97%B4-%EC%B6%94%EA%B0%80%EC%9D%98-%EC%B6%94%EC%B6%9C1
5. 파워 쿼리 편집기 열기
위 파일을 연 다음
데이터 탭에서 '쿼리 및 연결'을 누릅니다.
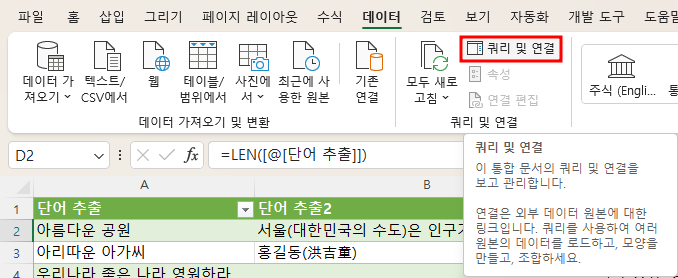
그러면 어제는 표시됐지만 숨겨져 있던 '쿼리 및 연결'창이 오른쪽에 나타납니다.
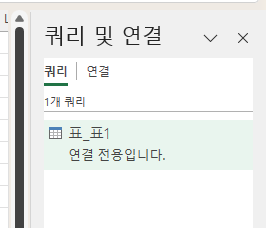
표_표1 하나만 있으므로 마우스 오른쪽 버튼을 누르고 편집 메뉴를 누거나, 더블 클릭해서 파워 쿼리 편집기를 열립니다.
1편에서 작업된 상태로 열리는데,
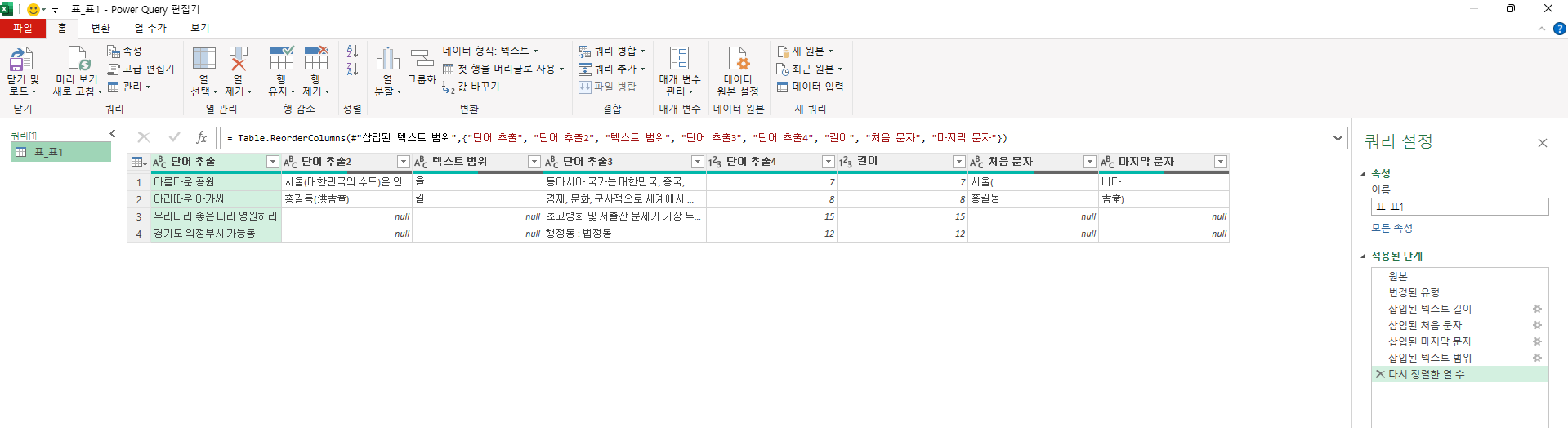
글자가 잘 안 보여서 쿼리를 확대해 보면 길이, 처음 문자, 마지막 문자가 보입니다. 텍스트 범위는 '단어 추출2' 오른쪽으로 옮겨서 안보입니다.

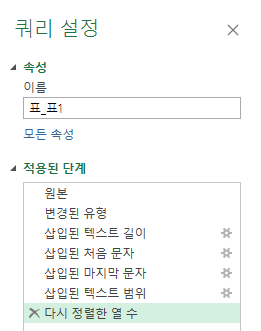
그리고, 오른쪽 '쿼리 설정' 창을 보면,
적용된 단계를 보면 그동안 작업한 내용을 알 수 있습니다.
6. 구분기호 앞 텍스트
가. 열 분할의 '구분 기호'와 비교
열 추가 탭에서 추출의 콤보 상자를 누르면 '구분 기호 앞 텍스트', '구분 기호 뒤 텍스트', '구분 기호 사이 텍스트',
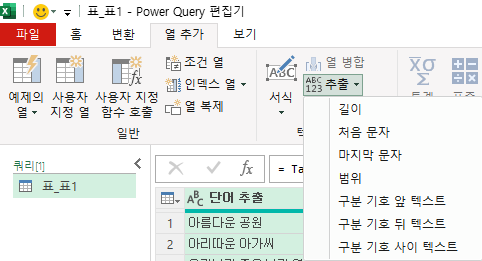
이것은 홈 탭의 열 분할 아래 '구분 기호 기준'과 용어는 비슷한데, 결과는 전혀 다릅니다.
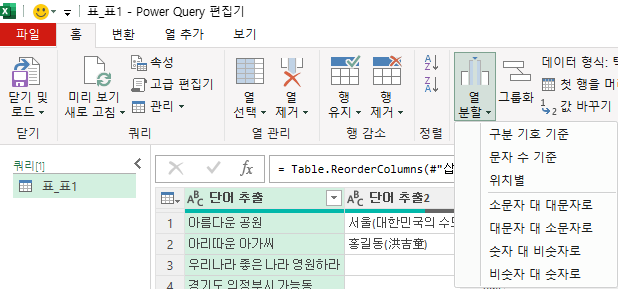
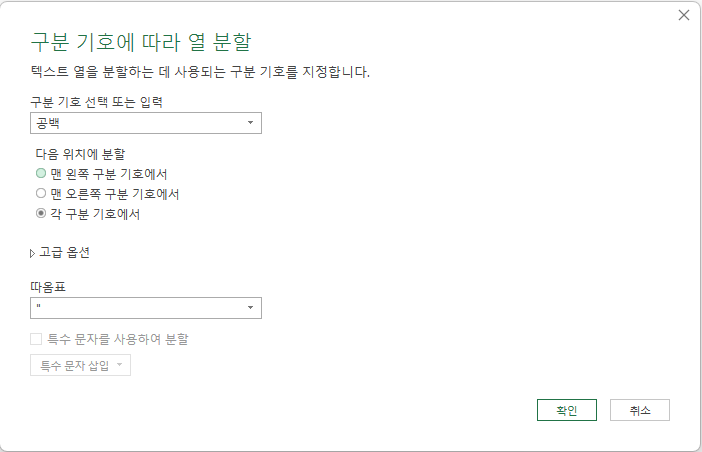
열 분할 아래 '구분 기호 기준'을 누르면 창이 하나 열리는데, 구분 기호 선택과, 위치에 따른 분할 옵션이 있습니다.
'맨 왼쪽 구분 기호에서' 등은 구분 기호가 분할의 기준인데
추출은 구분 기호를 기준으로 분리된 값을 추출해 오는 것이므로 다릅니다.
'경제, 문화, 군사적으로...'이란 문장을 예로 들면

,(쉼표)를 구분 기호로 열 분할의 '맨 왼쪽 구분 기호에서는'을 적용하면
'경제'와 '문화, 군사적으로'로 분할되는데
(단어 추출3.2가 맨 오른쪽에 추가되는데 열 이름을 끌어서 단어 추출3.1 오른쪽으로 이동했습니다),

추출의 '구분 기호 앞 텍스트'는 '경제'란 텍스트만 추출합니다.

나. 처음 문자, 마지막 문자, 범위와 비교
처음 문자의 경우 위치를 지정하는데, 위치가 구분자가 되는 점만 다르고, 구분 문자 앞 텍스트를 구해주므로, 추출의 '구분 기호 앞 텍스트'는 처음 문자(Left 함수)와 유사하고,
마찬가지로 '구분 기호 뒤 텍스트'와 '구분 기호 사이 텍스트'는 '마지막 문자'와 '범위'와 유사한 결과를 구해줍니다(Mid함수)
Left함수를 사용할 때는 Find함수와 결합하여 수식을 작성해야 하고, 찾는 값이 없을 때는 IfError함수를 이용해 에러 시 값을 지정해야 하는 등 복잡한데
예) 첫 번째 쉼표(,) 앞의 문자열 가져오는 수식 : =LEFT(C3,IFERROR(FIND(",",C3),LEN(C3)+1)-1)

이 값을 수식을 사용하지 않고 파워 쿼리를 이용해 쉽게 구할 수 있습니다.
다. 구분기호 앞 텍스트 실행
변환을 하면 기존 값이 대체되므로,
열 추가의 추출 > 구분기호 앞 텍스트를 해보겠습니다.
'단어 추출3'열에 커서를 두고, 열 추가의 추출 > 구분기호 앞 텍스트를 누르면
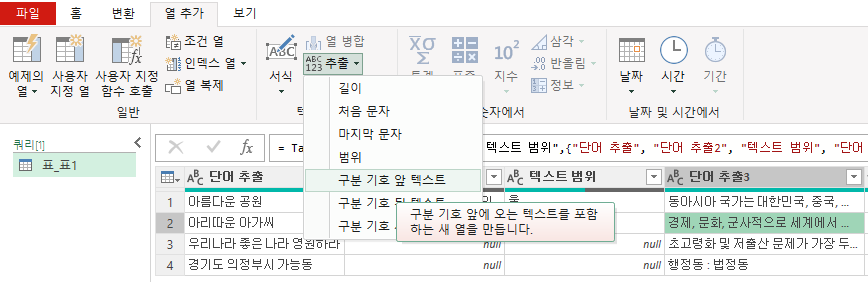
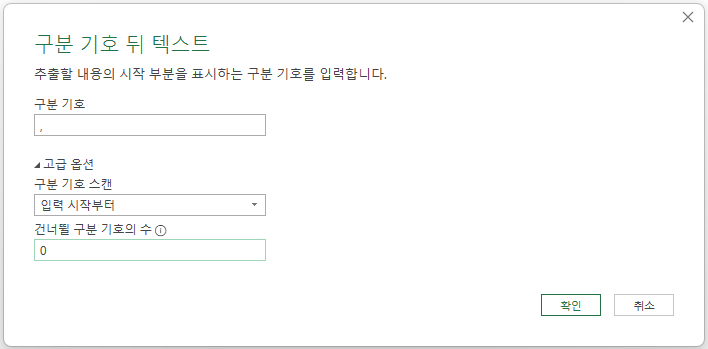
창이 열리면서 '구분 기호'를 입력하라고 하는데 쉼표(,)를 입력하고
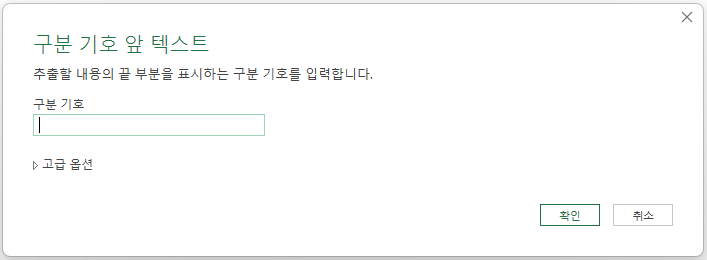
고급 옵션을 클릭하면 '구분 기호 스캔'과 '건너뛸 구분 기호의 수'가 표시되는데,
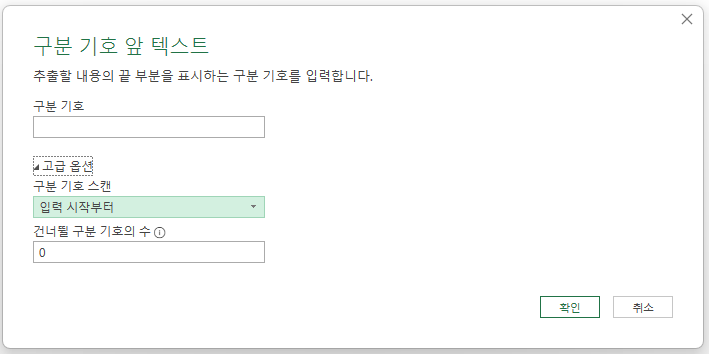
구분 기호 스캔 아래 콤보 상자를 누르면 '입력 시작부터'와 '입력 끝부터'란 옵션이 있습니다.
'입력 시작부터'는 왼쪽부터 구분 기호를 찾는 것이고, '입력 끝부터'는 오른쪽부터 구분 기호를 찾는 것입니다.
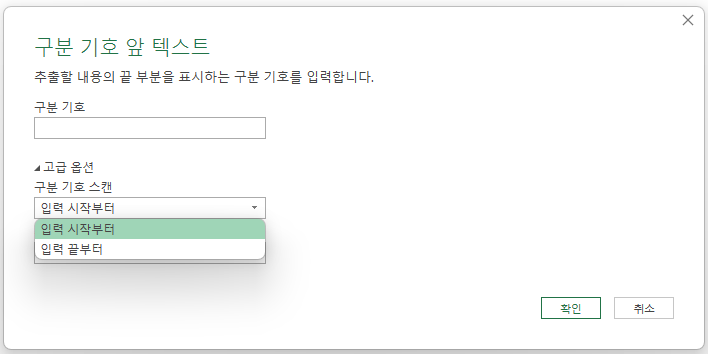
그리고, '건너뛸 구분 기호의 수'는 구분 기호가 여러 개 있을 때 몇 개를 건너뛸 것인지 정하는 것입니다.
아래와 같이 구분 기호로 ,(쉼표), 구분 기호 스캔 방법은 '입력 시작부터', '건너뛸 구분 기호의 수'는 1로 지정하고 확인 버튼을 누르면
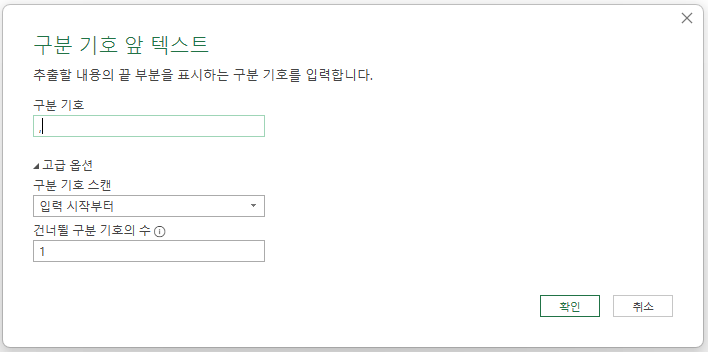
구분 기호가 두 개이상인 경우는 '경제, 문화'와 같이 두 번째 구분기호 앞까지 문자열을 가져오는데,
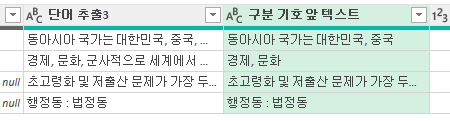
'행정동 : 법정동'과 같이 구분기호가 하나도 없거나 하나만 있을 경우는
원래 입력된 문자열 전체를 가져옵니다.
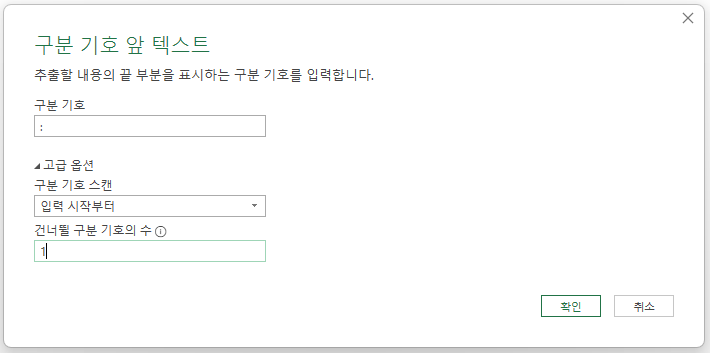
'단어 추출3'열의 4번째 레코드에 :(콜론)이 하나만 있으므로,
구분 기호를 :(콜론)으로 바꾸고, 고급 옵션은 '입력 시작부터'와 1로 지정하고 확인 버튼을 누르면
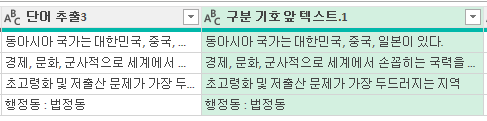
콜론이 1개뿐이 없기 때문에 기존 문장 전체를 추출해 줍니다.
'행정동 : 법정동'도 마찬가지입니다.
7. 구분기호 뒤 텍스트
구분 기호를 기준으로 뒤에 오는 텍스트를 추출해 주는 것입니다.
아래와 같이 구분 기호로 ,(쉼표), 구분 기호 스캔 방법은 '입력 끝부터', '건너뛸 구분 기호의 수'는 1로 지정하고 확인 버튼을 누르
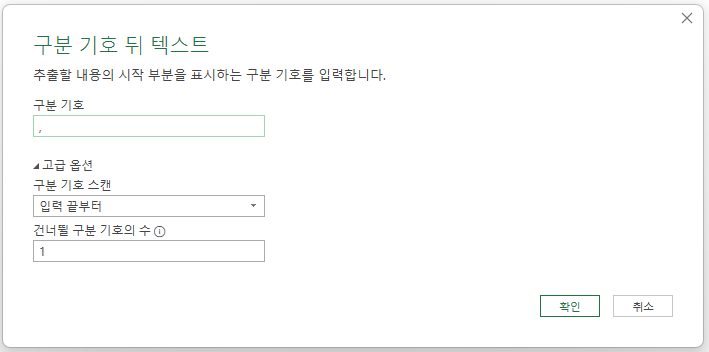
뒤부터 두 번째 ,(쉼표)의 위치를 찾아 그다음부터 문장을 추출해 줍니다.

따라서, '경제, 문화, 군사적으로...'에서 두 번째 쉼표가 경제 다음에 있으므로
'문화'이후의 문장이 추출된 것입니다.
행정동 : 법정동'은 두 번째 쉼표가 없으므로 모든 문장이 추출됐습니다.
'구분 기호 스캔' 방법을 '입력 시작부터'로 바꾸고 '건너뛸 구분 기호의 수'를 0으로 바꾸고 확인 버튼을 누르
첫 번째와 두 번째 레코드의 결괏값은 같은데,
세 번째와 네 번째 레코드의 경우는 쉼표가 없어 공백이 추출됩니다.

8. 구분 기호 사이 텍스트
구분 기호 사이에 있는 텍스트를 추출해 주는 것입니다.
변환하면 기존 텍스트가 대체되므로 열 추가로 해보겠습니다.
단어 추출2를 기준으로 열 추가 > 추출 > 구분 기호 사이 텍스트를 선택하

시작과 종결 구분 기호를 묻고,
스캔 방법을 입력 시작부터 할 것인지, 몇 개를 건너뛸 것인지를 물어보는데,
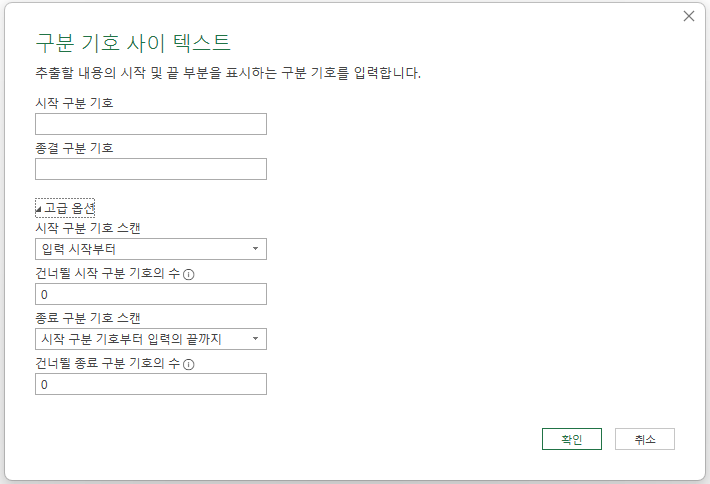
시작 구분 기호로는 ([여는 괄호]를 입력하고, 종결 구분 기호로는 )[닫는 괄호]를 입력합니다.
그리고, 고급 옵션은 그대로 두고 확인 버튼을 누른 다음 맨 오른쪽에 있는 '구분 기호 사이 텍스트'열을 단어 추출2 오른쪽으로 끌고 오면 아래와 같이 '대한민국의 수도'와 洪吉童이 추출됩니다.
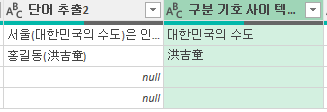
파워 쿼리는 위와 같이 함수를 알지 않더라도 쉽게 데이터를 추출해 주는 장점이 있습니다.
9. 닫기 및 로드
홈 탭에서 '닫기 및 로드'의 윗부분을 누르면
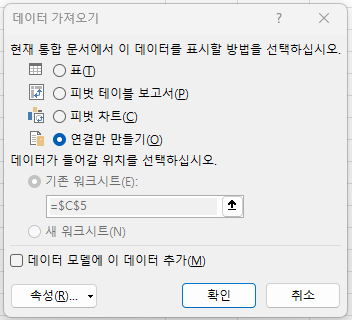
기존에 '연결만 만들기'로 설정하였으므로
'쿼리 및 연결'창에 연결 전용으로 만들어집니다.
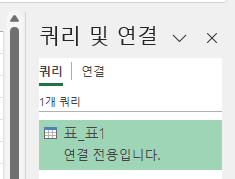
따라서, 작업한 내용을 워크 시트에 반영하려면 표_표1에서 마우스 오른쪽 버튼을 누른 후
'다음으로 로드' 메뉴를 눌러야 합니다.

그러면 '연결만 만들기'에 선택되어 있는데, '표'를 선택하고,
위치는 '새 워크시트'를 선택하고 확인 버튼을 누르
현재까지 작업된 모든 내용이 아래와 같이 새로운 시트에

표로 추가됩니다.


'Excel - 파워 쿼리' 카테고리의 다른 글
| 파워 쿼리와 VLookup 비교(1) (0) | 2024.04.17 |
|---|---|
| 열방향의 자료를 행방향으로 10개씩 쌓아올리기(1) (파워 쿼리 UI 이용) (0) | 2024.02.14 |
| (파워 쿼리) 변환의 추출과 열 추가의 추출(1) (0) | 2023.07.10 |
| 데이터 탭의 텍스트 나누기와 파워 쿼리의 열 분할 (0) | 2023.07.07 |
| 열이 다른 테이블(표)의 쿼리 추가 (0) | 2023.07.05 |