1편에서는 도수분포표를 데이터 분석 도구 명령을 이용해서 구했는데,
함수를 이용해 구간별 빈도수를 구하는 것이 Frequency 함수입니다.
1. 구문
FREQUENCY(data_array, bins_array)
data_array : 필수 요소입니다. 빈도를 계산할 값 집합의 참조 또는 배열입니다.
bins_array : 필수 요소입니다. data_array에서 값을 분류할 간격의 참조 또는 배열입니다.
1편에서 data_array는 입력 범위, bins_array는 계급 구간이라고 명명했습니다.

2. 엑셀 버전별 차이
Microsoft 365용 Excel Mac용 Microsoft 365용 Excel 웹용 Excel Excel 2021 Mac용 Excel 2021 Excel 2019 Mac용 Excel 2019 Excel 2016 Mac용 Excel 2016 Excel 2013 Excel 2010 Excel 2007 Mac용 Excel 2011 Excel Starter 2010
이므로 대부분의 버전에서 사용 가능한 함수입니다.
그러나, Microsoft 365과 다른 버전은 아래와 같은 차이점이 있습니다.
최신 버전의 Microsoft 365가 있는 경우, 출력 범위의 왼쪽 상단 셀에 수식을 간단히 입력한 다음 ENTER 키를 눌러 동적 배열 수식으로 반환이 되는데,
다른 버전이라면 먼저 출력 범위를 선택하여 출력 범위의 왼쪽 상단 셀에 수식을 입력한 다음, 출력을 위해 Ctrl+Shift+Enter를 눌러 수식을 레거시 배열 수식으로 입력해야 합니다. 그러면 수식의 시작과 끝에 중괄호가 삽입됩니다.
3. 사용 예
가. 예제 1
(1) Microsoft 365버전
i1셀에 =FREQUENCY(C2:C14,F2:F11)라고 입력하고 엔터키를 누르면
구간별 빈도수가 표시되고, 배열로 값이 반환되므로 파란색 선으로 둘러싸여져 있습니다.
주의해야 할 것은 반환된 배열의 요소 개수가 bins_array의 요소 개수보다 하나 더 많다는 것입니다. 다시 말해 10행에 있는 0은 1000을 초과한 구간의 개수를 말합니다.
(2) 레거시 배열 수식
K1셀부터 K11셀까지 마우스로 끌어서 범위를 선택한 후
수식은 똑같이 =FREQUENCY(C2:C14,F2:F11)라고 입력한 후 Ctrl+Shift+Enter(CSE)키를 누르면, 수식에 중괄호 표시가 생기고, 출력 범위에 파란색 테두리가 보이지 않습니다.
빈도수만 표시되므로 왼쪽에 계급 구간을 표시하거나,
구간이 있는 F열 오른쪽 G2셀에 수식을 입력하는 것이 좋습니다.

나. 예제 2
구간과 같은 값이 있을 때 어떻게 처리되는지 살펴보겠습니다.
Microsoft 365기준으로 설명합니다.
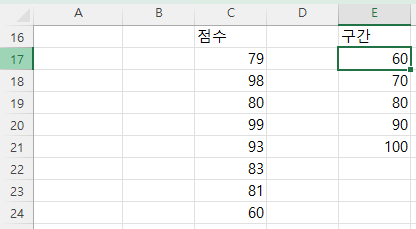
구간 옆인 F17셀에 커서를 두고
=FREQUENCY(C17:C24,E17:E21) 라고 입력하고 엔터키를 누르면

첫번째 구간 60은 60까지인데, 60점까지는 60점 1개이므로 1이라고 표시되고,
70점까지는 없고,
80점까지는 79점, 80점 각 한 개씩 2개이므로 2로 표시되고,
90점까지는 83점이 1개, 81점이 1개이므로 2,
100점까지는 98, 99, 93점 총 3개이므로 3이 반환됩니다.
다. 예제 3
FREQUENCY 함수에서 빈 셀과 텍스트는 무시됩니다.
히스토그램에서는 빈 셀과 텍스트가 있으면 에러가 발생하는 것과 다른 점입니다.
아래와 같이 C29셀은 빈 셀로 하고, C32셀에 빵점이라고 입력하고
히스토그램을 실행하면(입력 범위 C27:C34, 계급 구간 : B27:B31, 출력 범위 : F27)

입력 범위에 숫자가 아닌 값이 있다고 하면서 처리가 되지 않고, 위 히스토그램 입력 상자로 돌아갑니다.

그러나, F27셀에 =FREQUENCY(C27:C34,E27:E31) 라고 입력하고 엔터키를 누르면 에러 없이 값이 반환되는데,
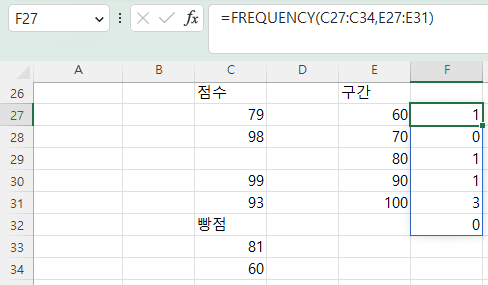
빈 셀과 텍스트가 무시되므로, 17행부터 있는 데이터 처리와 비교하면

80점과 83점이 없어졌으므로
80점까지가 2에서 1로, 90점까지가 2에서 1로 줄었습니다.
라. 예제 4
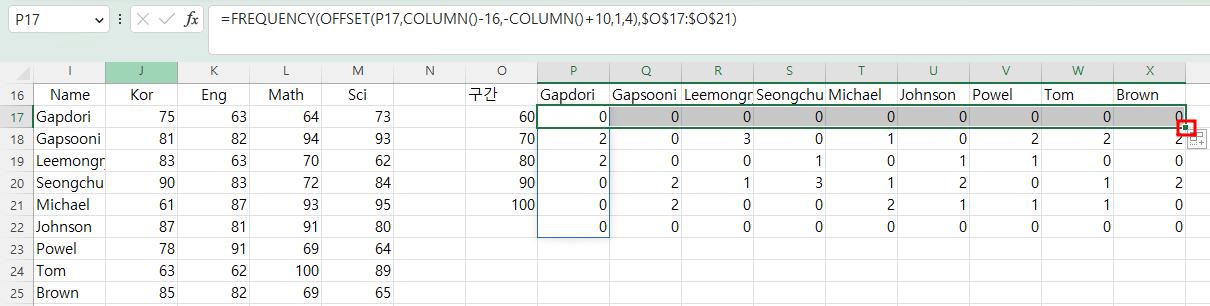
가로로 된 데이터라도 Frequency 함수의 결과는 세로로 반환됩니다.
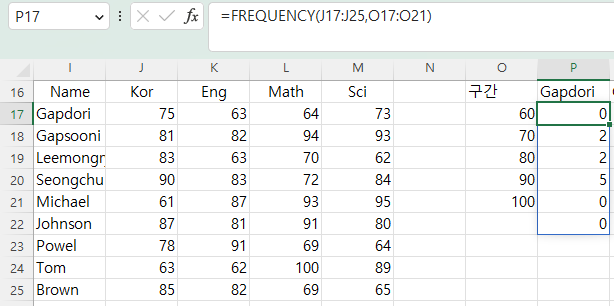
아래와 같이 성명별 과목별 점수가 있을 때
성명별로 분포를 구하고자 할 경우는

P17셀에 =FREQUENCY(J17:J25,O17:O21) 이라고 입력 범위는 가로로 지정해도
결과는 세로 배열로 반환됩니다.
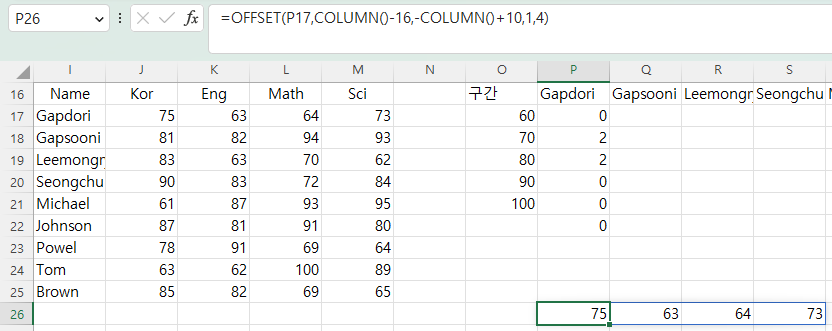
입력 범위가 오른쪽으로 한 칸 이동할 때 한 줄씩 내려가야 하므로
입력 범위를 Offset함수를 이용해
OFFSET(P17,COLUMN()-16,-COLUMN()+10,1,4) 라고 지정합니다.

Offset함수의 구문은 OFFSET(reference, rows, cols, [height], [width])으로
rows는 현재 행은 0, 아래로 내려갈 때는 +, 위로 올라갈 때는 -,
cols는 현재 열은 0, 오른쪽으로 갈 때는 +, 왼쪽으로 이동할 때는 -,
height는 높이, width는 너비입니다.
따라서, OFFSET(P17,COLUMN()-16,-COLUMN()+10,1,4) 는
P17셀을 기준으로 Column()-16만큼 행 방향으로 이동하는데;
Column()함수는 인수가 없으면 현재 열의 번호를 반환하므로, P열은 16이고,
COLUMN()-16은 0이 됩니다.
그러나, 오른쪽으로 수식을 복사하게 되면 Column()이 17이 되므로 COLUMN()-16은 1이 되므로 한 줄 아래로 이동하게 됩니다.
-COLUMN()+10은 -16에 10을 더하면 -6이 되고, 오른쪽으로 수식을 복사하게 되면 -17+10은 -7이 되므로 P열에서 왼쪽으로 7칸 이동한 J열을 가리키게 됩니다.
그리고, height는 1, width는 4이므로, OFFSET(P17,COLUMN()-16,-COLUMN()+10,1,4)의 결과는 J17:M17이 됩니다.
수식 입력 줄에서 OFFSET(P17,COLUMN()-16,-COLUMN()+10,1,4)를 복사한 후
P26셀에 커서를 놓고 =을 입력한 후 붙여 넣고 엔터 키를 누르면 J17셀에서 M17셀까지의 숫자 75,63,64,73을 반환합니다.
이제 P17셀의 채우기 핸들을 X17셀까지 끌면 해당 자에 대한 분포표가 모두 만들어집니다.
'Excel' 카테고리의 다른 글
| And, Or, Not 함수 (3) | 2023.06.09 |
|---|---|
| Vlookup함수 - 유사 일치 (0) | 2023.06.08 |
| 히스토그램과 Frequency 함수(1) (0) | 2023.05.31 |
| 중간값에 해당하는 값이 2개일 때 2개 모두 표시하기 (0) | 2023.05.30 |
| 조건부 서식 - 둘 이상 조건에 맞는 줄에 색칠하기 (0) | 2023.05.25 |