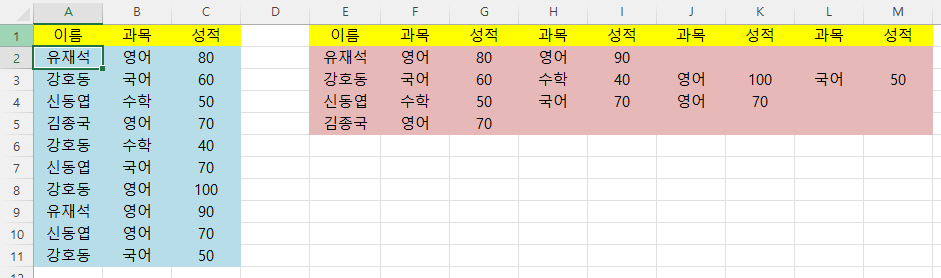
1. 문제
왼쪽의 세로로 된 데이터를 오른쪽과 같이 가로로 배치하려고 합니다.
2. 해법
Microsoft 365 기준으로 설명하려고 합니다.
가. 이름 추출하기(Unique 함수)
중복된 이름을 하나씩만 추출하려면
Unique 함수를 사용하면 됩니다.
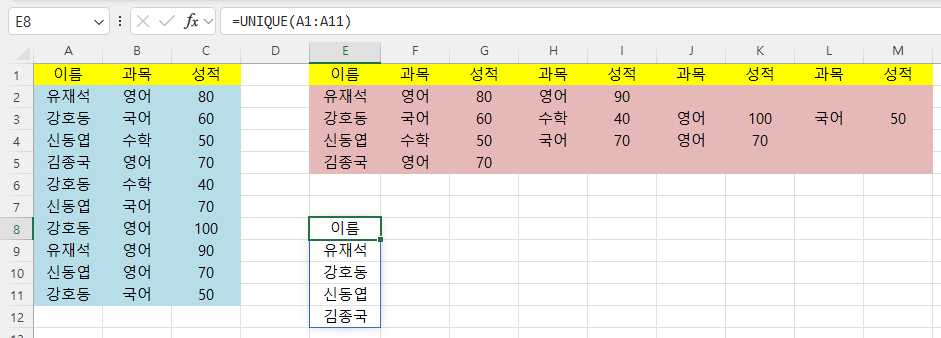
수식은 =unique(a1:a11)입니다.
365 버전은 E8에서 E12셀에서 보는 바와 같이 동적 배열형태로 값이 반환되고,
파란색 실선으로 테두리가 그려집니다.
나. 과목, 성적을 가로로 배치하기
머리글 부분은 따로 설명하고,
먼저 과목명과 성적 부분만 먼저 2개씩 가로로 배치해 보겠습니다.
(1) Filter 함수 적용
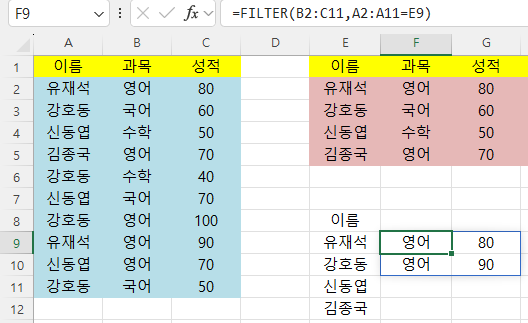
=FILTER(B2:C11,A2:A11=E9)라고 하면
E9셀의 이름에 맞는 B2에서 C11의 데이터가 아래와 같이
세로로 표시됩니다.
(2) ToRow 함수 적용
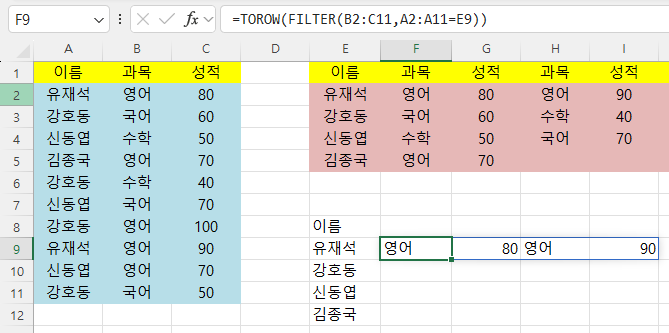
세로로 된 데이터를 한 줄로 만들려면 ToRow함수를 사용하면 됩니다.
=torow(FILTER(B2:C11,A2:A11=E9))
(3) ByRow 실패
위와 같이 한 줄만 결과가 표시되므로
행별로 처리하는 ByRow함수를 사용하면 되지 않을까 해서
=BYROW($A$2:$A$11,LAMBDA(name,FILTER($B$2:$C$11,name=E9)))라고 하면
#VALUE! 에러가 발생하고,
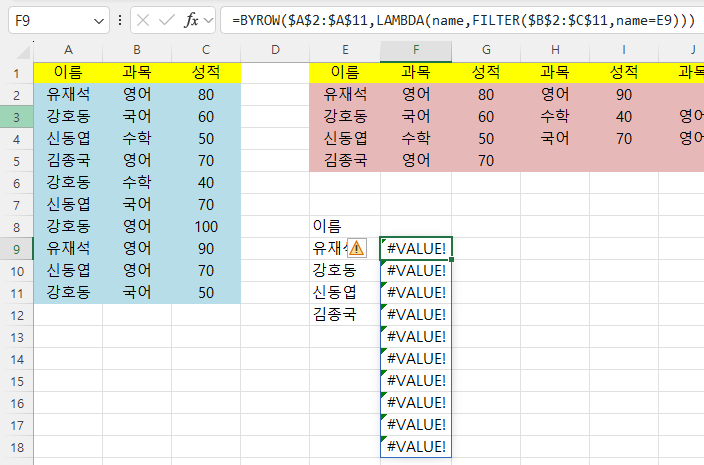
=BYROW(UNIQUE($A$2:$A$11),LAMBDA(name,FILTER($B$2:$C$11,$A$2:$A$11=name)))라고 하면
#CALC! 에러가 발생합니다.
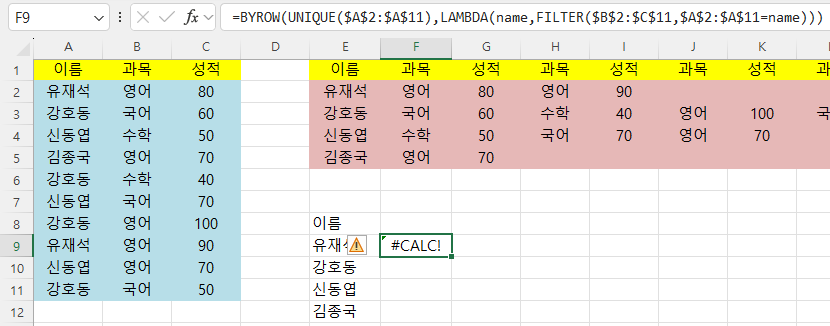
(4) Reduce 함수 사용
ByRow 함수는 배열을 반환하는데 반해서 Reduce 함수는 단일 값을 반환하는 차이점이 있습니다.
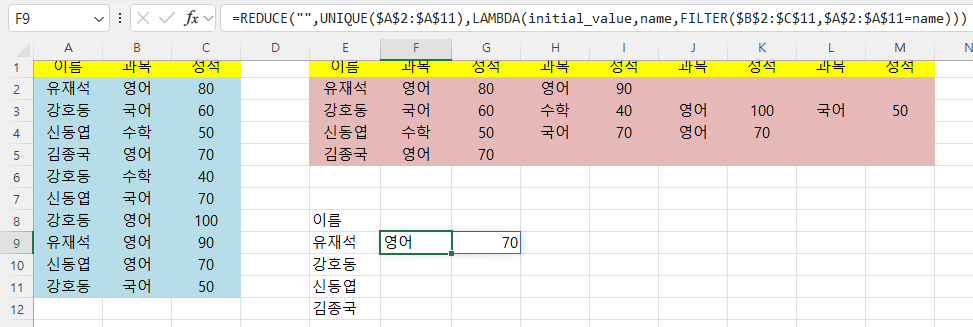
=REDUCE("",UNIQUE($A$2:$A$11),LAMBDA(initial_value,name,FILTER($B$2:$C$11,$A$2:$A$11=name)))
라고 하니
맨 아래 김종국의 영어, 70만 표시하고 끝납니다.
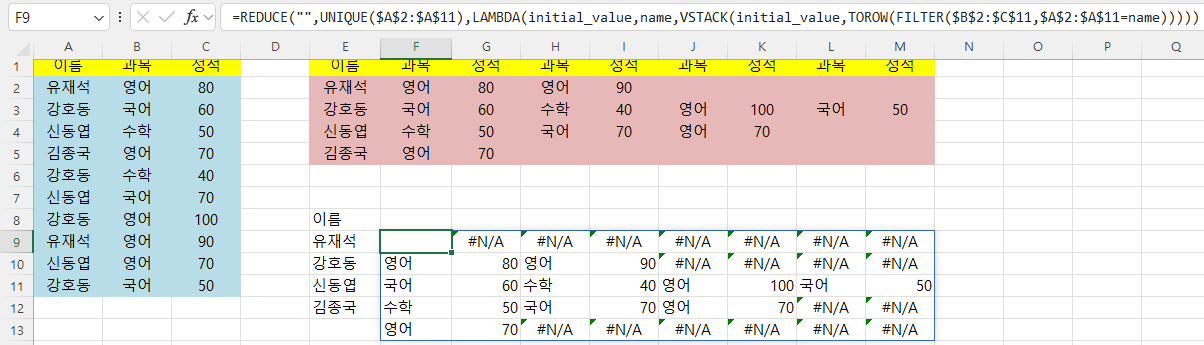
따라서 중간값을 저장하도록 VStack 함수를 사용해야 합니다.
=REDUCE("",UNIQUE($A$2:$A$11),LAMBDA(initial_value,name,VSTACK(initial_value,TOROW(FILTER($B$2:$C$11,$A$2:$A$11=name)))))
에서
VSTACK(initial_value,TOROW(FILTER($B$2:$C$11,$A$2:$A$11=name)))
부분을 살펴보면 initital_value("")가 있고,
TOROW(FILTER($B$2:$C$11,$A$2:$A$11=name))가 있는데,
이 부분이 한 줄씩 성명에 해당하는 과목과 점수를 반환하는 부분입니다.
(5) IfNA 함수 사용
그러면 첫 줄 첫 셀은 공백이고, 이후 부분은 이름에 매치되는 데이터를 표시하는데 조건에 맞는 데이터가 없으면 #N/A 오류가 표시됩니다.
따라서, #N/A를 공백으로 바꾸기 위해
IfError나 IfNA 함수를 사용하면 되는데,
IfNa 함수를 사용하면
=IFNA(REDUCE("",UNIQUE($A$2:$A$11),LAMBDA(initial_value,name,VSTACK(initial_value,TOROW(FILTER($B$2:$C$11,$A$2:$A$11=name))))),"")가 되고,
아래와 같이 공백으로 표시됩니다.
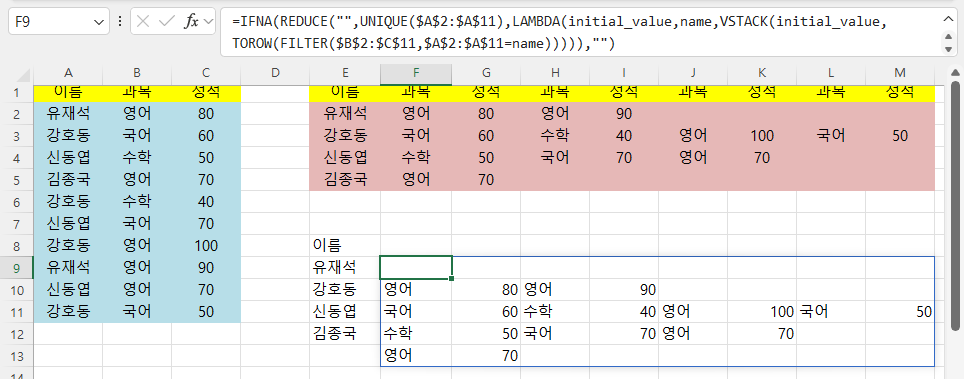
(6) Drop 함수 사용
첫 줄은 필요 없으므로
Drop 함수를 이용해 제거합니다.
Drop함수의 구문은
=DROP(array, rows,[columns])로서
배열을 입력한 다음 삭제할 행수와 열수를 입력합니다.
맨 위 1줄만 삭제하면 되므로
=drop(배열,1)이라고 하면 됩니다.
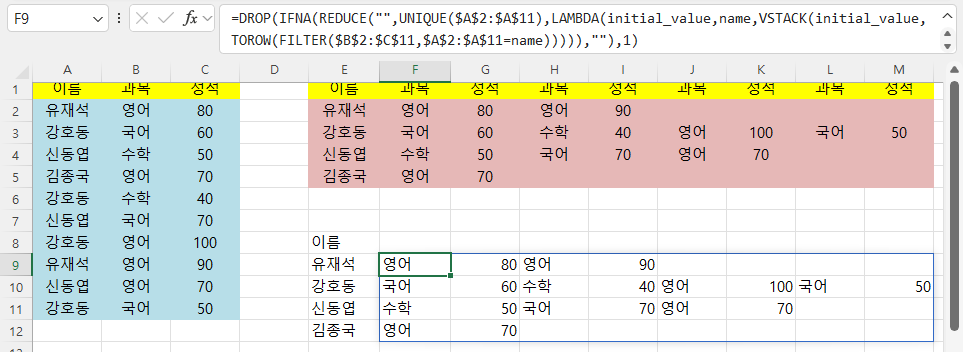
=DROP(IFNA(REDUCE("",UNIQUE($A$2:$A$11),LAMBDA(initial_value,name,VSTACK(initial_value,TOROW(FILTER($B$2:$C$11,$A$2:$A$11=name))))),""),1)
첫 줄이 제거되어 왼쪽 이름과 오른쪽의 과목, 성적이 일치합니다.
(7) 과목, 성적을 반복해서 표시하기(MakeArray 함수)
배열을 만들어야 하므로
MakeArray 함수를 사용합니다.
MakeArray 함수의 구문은
=MAKEARRAY(rows, cols, lambda(행, 열))로서
행수, 열수, lambda(행, 열, 함수)가 됩니다.
이상하게 다른 함수도 Lambda 안의 인수인 함수는 생략하고 구문이 표시됩니다.
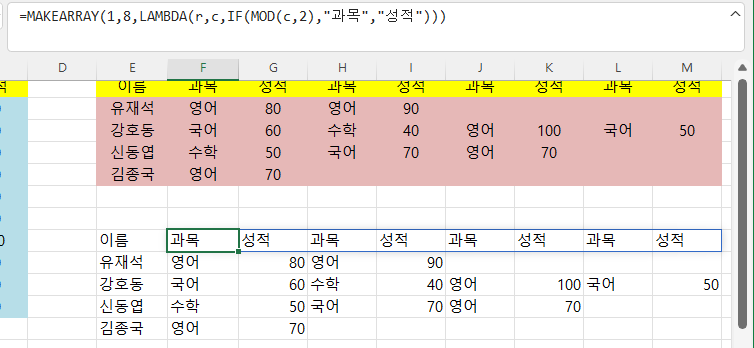
1행 8열로 만드는데,
과목과 성적인 반복되어야 하므로
Mod 함수를 이용해 홀수일 때는 "고목", 짝수일 때는 "성적"을 표시하도록 하면 됩니다.
=MAKEARRAY(1,8,LAMBDA(r,c,IF(MOD(c,2),"과목","성적")))
이때 MOD(c,2)에서 c는 1부터 시작하므로 1이 반환되고, 1은 참이므로 "=1"은 쓰지 않아도 됩니다.
이제 8을 강제로 입력하지 않고 수식으로 입력하는 것을 고민해야 하는데,
이름의 개수에 2를 곱한 것입니다.
먼저 이름의 개수를 COUNTIF(A2:A11,UNIQUE(A2:A11))로 구해보면
2,4,3,1이 되므로 다시 최댓값을 Max함수로 구하면 됩니다.
따라서, 최종 수식은
=MAKEARRAY(1,MAX(COUNTIF(A2:A11,UNIQUE(A2:A11)))*2,LAMBDA(r,c,IF(MOD(c,2),"과목","성적")))
가 됩니다.
(8) 과목, 성적 머리글과 데이터 연결해서 표시하기(VStack 함수)
세로로 쌍아야 하므로 VStack함수를 다시 사용합니다.
=VSTACK(MAKEARRAY(1,MAX(COUNTIF(A2:A11,UNIQUE(A2:A11)))*2,LAMBDA(r,c,IF(MOD(c,2),"과목","성적"))),DROP(IFNA(REDUCE("",UNIQUE($A$2:$A$11),LAMBDA(initial_value,name,VSTACK(initial_value,TOROW(FILTER($B$2:$C$11,$A$2:$A$11=name))))),""),1))

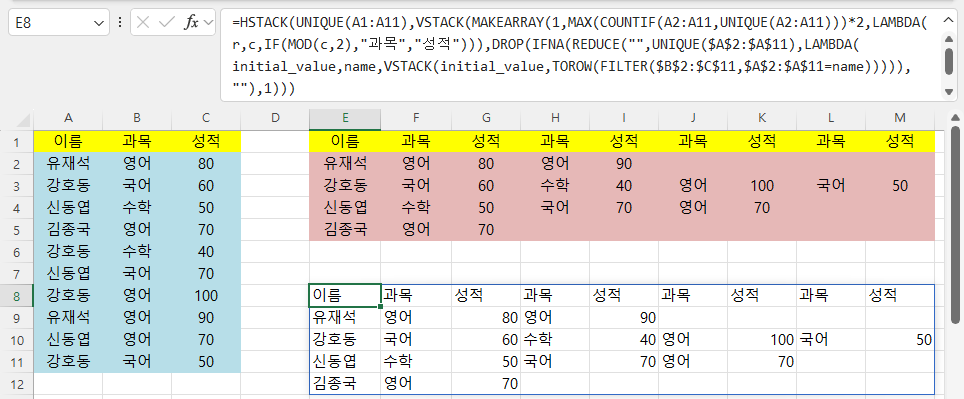
다. 이름과 과목, 성적을 가로로 연결하기(HStack 함수)
이름과 과목, 성적은 옆으로 되어 있으므로
HStack 함수를 이용해 결합하면 됩니다.
=HSTACK(UNIQUE(A1:A11),VSTACK(MAKEARRAY(1,MAX(COUNTIF(A2:A11,UNIQUE(A2:A11)))*2,LAMBDA(r,c,IF(MOD(c,2),"과목","성적"))),DROP(IFNA(REDUCE("",UNIQUE($A$2:$A$11),LAMBDA(initial_value,name,VSTACK(initial_value,TOROW(FILTER($B$2:$C$11,$A$2:$A$11=name))))),""),1)))
라. Let 함수를 이용해 중복되는 부분을 이름으로 정의하기
(1) 이름과 값 정의하기
중복되는 부분은 A1:A11, A2:A11, B2:C11, Unique(A2:A11)입니다.
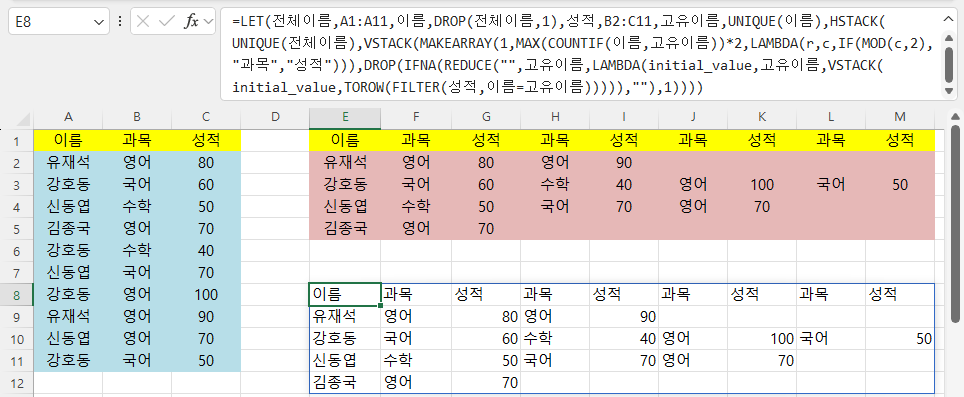
=LET(전체이름,A1:A11,이름,DROP(전체이름,1),성적,B2:C11,고유이름,UNIQUE(이름)
라고, 이름과 값을 정의했습니다.
이때 이름,DROP(전체이름,1)과 같이
정의된 이름(여기서는 '전체이름')을 이용해 다른 이름(여기서는 '이름')을 함수(여기서는 Drop)를 이용해 정의할 수 있습니다.
고유이름,UNIQUE(이름)에서는 이름을 Unique함수를 이용해 고유한 값만 추출한 후 고유이름에 할당했습니다.
(2) 이름을 이용해 수식 정리
수식에서 해당하는 부분은 정의된 이름으로 대체했습니다.
HSTACK(UNIQUE(전체이름),VSTACK(MAKEARRAY(1,MAX(COUNTIF(이름,고유이름))*2,LAMBDA(r,c,IF(MOD(c,2),"과목","성적"))),DROP(IFNA(REDUCE("",고유이름,LAMBDA(initial_value,uniq_name,VSTACK(initial_value,TOROW(FILTER(성적,이름=uniq_name))))),""),1)))
DROP(IFNA(REDUCE("",고유이름,LAMBDA(initial_value,고유이름,VSTACK(initial_value,TOROW(FILTER(성적,이름=고유이름))))),""),1) 중에서
Reduce 함수 내에 고유이름을 사용한 다음
Lambda함수에 변수를 전달하는데 같은 이름이 '고유이름'을 사용해도 됩니다.
'Excel' 카테고리의 다른 글
| 문자열로 된 수식의 값 계산하기 (0) | 2024.03.18 |
|---|---|
| 단어 포함 합계 구하기 (0) | 2024.03.18 |
| 제품, 잔량별 생산일수 기준 불량 여부 판단 (2) | 2024.03.14 |
| 중복된 값은 제외하고 문자열 연결하기 (0) | 2024.03.12 |
| 근무표 유형 변경하기(365 버전용) (0) | 2024.03.11 |